
A common issue I see is understanding the flow of commands, events and queries within a typical CQRS Event Sourcing based system. The following post is designed to clear up what happens at each step. Hopefully, this will help you to reason about your code and what each part does.
What is CQRS and what does it stand for?
CQRS stands for Command Query Responsibility Segregation. It is an architectural programming pattern. Based on the idea that there are significant benefits resulting from separating code for the ‘write’ and the ‘read’ parts of an application.
This makes more sense when you consider the number of reads to a database in order to display information in a typical business application, such as a blog CMS or customer relationship manager, compared to the number of times you write to the database. Clearly, the reads vastly outnumber the writes. And yet typical databases and code are optimised for writes.
This gives rise to the idea that separating the command query parts of the application gives will lead to some interesting benefits. Not surprisingly it also throws up some interesting challenges such as eventual consistency. Incidentally, if you are looking for a way to handle eventual consistency check out this post: 4 Ways to Handle Eventual Consistency on the UI
What is Event Sourcing?
Event sourcing is a way of persisting data that includes the order and timing in which it was changed. Think of event sourcing as an append-only log of what happened. This is distinct from storing the end result, which is how data is typically stored in a relational database. Event sourcing and CQRS are often used together but are separate patterns. An event is defined as something which changes the state of the application. For example a deposit into a bank account would count as a state change. Rather than storing the balance after the operation, in event sourcing the information about the state change would be stored as an event.
Events can then be published and subscribed to enable other operations to take place as described later on in this article.
When Should You Use CQRS and Event Sourcing?
In my experience the major problem using the CQRS architectural pattern is the learning curve for developers starting out with CQRS it’s self. A big factor in deciding if it’s right for part or all of the next project should be how familiar your team is.
It’s a bit of a catch 22.
Using CQRS can and will offer the right project some considerable advantages. CQRS and Event Sourcing grew out of the Domain-driven design (DDD) movement. A movement designed to handle, reduce and control the growing complexity of software in a typical development project. As a result, it’s ideally suited to more complex domains. The structure allows you to handle business logic, different models and potentially complicated business rules in a simpler way.
It’s suited to problems that have a clear domain model. And given the value attained through event sourcing, it is best suited to business-critical applications. There is an argument to develop less critical software using these ideas as a training ground for an under-experienced team.
As with many other top-level architectural and design patterns, elements can be plucked out for use independently. For example, separating out the query responsibility and read model can bring benefits to other styles of application. Or the way the domain objects are isolated from external dependencies can help model business logic more efficiently. Not to mention a vastly simpler data model on the write side.
CQRS and Event Sourcing with Microservices
With the increasing popularity of microservices, it is worth mentioning that both event sourcing and event sourcing and CQRS are both well suited and worth examining. Microservices architecture shares some of the ideas found and the application of domain events and use of event streams are concepts that can dovetail with microservices applications.
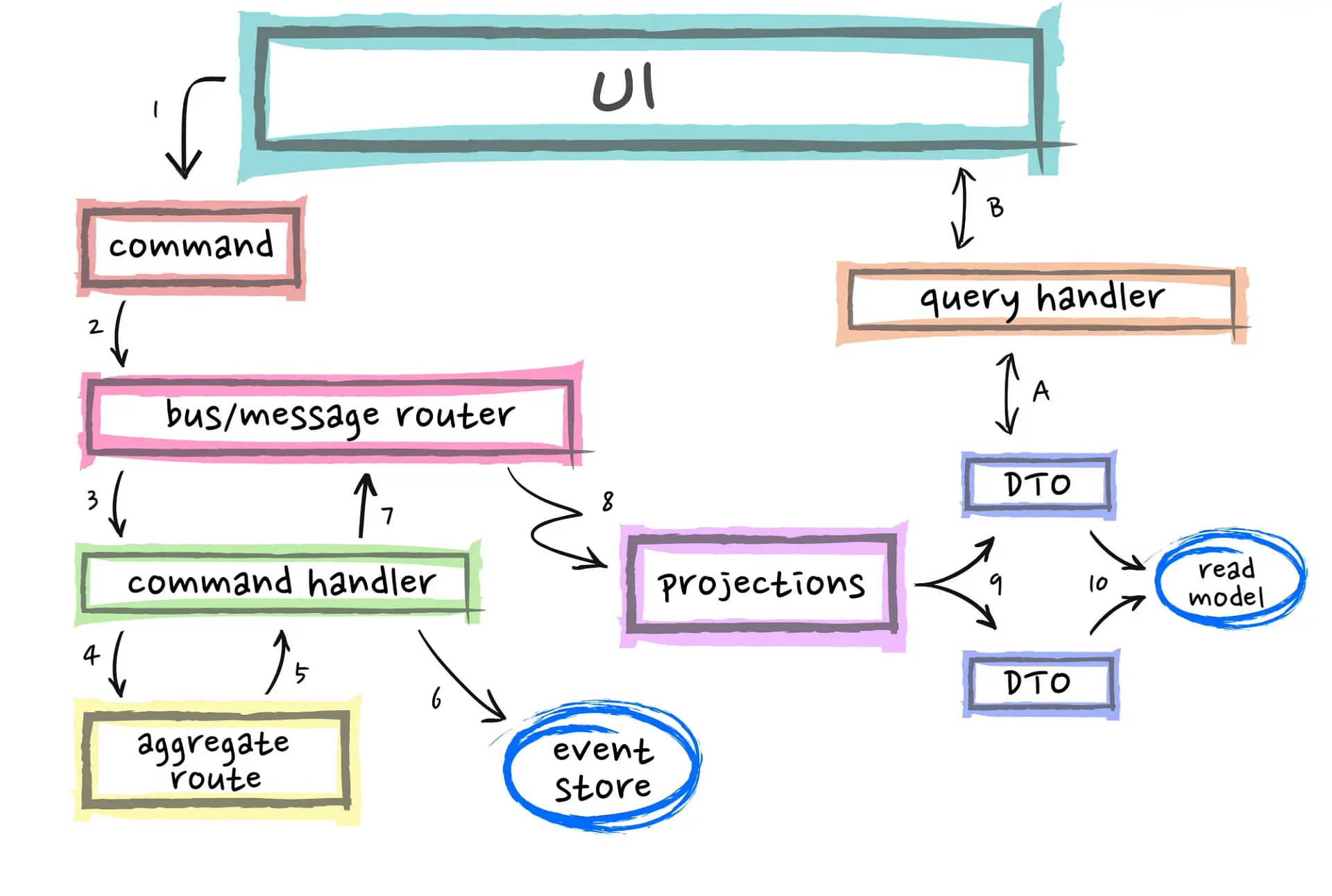
Given that premise, the following is typically how you would structure the various elements of the architecture.
1. A Command is generated from the UI
The UI displays data to the user. The user generates a command by carrying out some task. This implies a different style of user interface sometimes known as a Task-Based UI.
UI’s today often reflect the CRUD (Create Read Update Delete) idea where data is laid out and you make changes. In contrast, a task-based UI leads a user through a task. To differentiate this better look at the following example:
Changing an address.
In a CRUD based system, the address would be displayed. The user would edit the parts which need to change and thus the address is changed. But the system would not know why the address was changed. Was it due to a spelling mistake or because the customer has moved house?
In contrast, a task-based approach would allow the user to request to change the address because the customer is moving house. Rather than simply edit the data, best practices in CQRS would suggest building up a command model designed to reflect what the application needs to do. This can be of great importance to a business as it may trigger new offers or change the perceived risk etc. This way a domain object begins to reflect the real-world operations of the application it’s self.
This approach also changes the was your software system handles application state. More on domain events later on.
This approach does require a small re-think into how to do validation operations. I won’t go into detail here but I offer some insights into smart ways to validate your CQRS events here: How To Validate Commands in a CQRS Application
2. The Message Router or Bus receives the command
The message bus or messaging system is responsible for routing the command to its handler. Each command by definition is handled by a single handler and typically within a transaction.
This approach of routing the command allows your system to remain flexible and easy to maintain. You can create a pipeline for every command to follow which could do things like checking a user has permission and superficial validation and or record application performance data. The options are endless.
To illustrate the flexibility, consider a restaurant.
Imagine the interconnected function and method calls in the following system:
- You take a seat, give your order to the waiter
- The order is sent to the kitchen.
- The chefs prepare the food.
- When it’s ready the waiter takes it to the appropriate table.
- Once the customer has finished they request the bill.
- The manager prepares the bill
- The waiter takes the payment.
- The customer leaves.
Now consider the complexity of the following changes.
Change 1: The manager takes you to your seat and introduces you to the drinks waiter who takes your drinks order.
Change 2: Drinks are served
Change 3: The service waiter arrives after a suitable delay to take the food order.
Change 4: The customer pays at the bar rather than at the table.
In a tightly coupled application, these changes would represent relatively significant changes to the application.
Alternatively, in a CQRS and Event Sourced architecture, many of the commands are the same and are simply called in a different order or new routes added to handle new use cases. I’m not claiming this is any sort of silver bullet but what might otherwise be a major change is often much simpler when following this design pattern.
3. The handler prepares the aggregate root
The aggregate root is the heart of the CQRS pattern. It is where the domain models are developed. Everything that happens here is happening on the ‘write side’ or with the ‘write model’. The key thing to note about the write model is that is not designed for reading. Sounds obvious. But the number of times I see people asking how to query a domain model. But if you’re new to this then the idea that you can’t query a domain model is a little odd. But it is precisely this command query segregation that brings a cleaner less complex code solution to the business problem.
It should also be noted that a domain model is NOT a data model as seen in a more database first approach. A domain model is the same as tables and relations in a typical relational database.
The handler news up a aggregate root and applies all previous events to it from the event log or more accurately the event store. This brings the AR (aggregate root) up to the latest state. This is typically very fast, even with thousands of events, however, if this becomes a performance bottleneck, a snapshotting process can be adopted to overcome this issue. While one doesn’t have to use the event sourcing pattern, you can see how well it dovetails in here.
Aggregate roots are what is commonly known as ‘domain objects’ or ‘write model’. These are distinct from typical domain layers objects as they have no getters and setters (other than a getter for the ID). These objects are not designed to be queryable. They contain all the functionality and or other classes designed to perform some business role. I.e. they aggregate everything needed to handle the business logic.
4. The command is issued
Once the AR is up to date the command is issued. The AR then ensures it can run the command and works out what would need to change but DOESN’T at this point change anything. Instead, it builds up the event or events that need to be applied to actually change its state. It then applies these events to itself. This part is crucial and is what allows ‘events’ to be re-run in the future and is at the heart of event sourcing. The command phase can be thought of as the behaviour and the ‘apply’ phase is the state transition that happens within the domain model it’s self.
5. The command handler requests the changes
At this point, assuming no exceptions have been raised, the command handler requests the uncommitted changes. Note that no persistence has actually taken place yet. The domain objects have no dependencies on external services. This makes them much easier to write and ensures they are not polluted by persistence requirements (I’m looking at you Entity Framework).
6. The command handler requests persistence of the uncommitted events to the event store
Here is when an event storage service comes into play. Its responsibility is to persist the events in order and also to ensure that no concurrency conflicts occur. You can read up on how to do this on a previous post of mine: How to handle concurrency issues in a CQRS Event Sourced system.
It is critical the event store persists the events successfully before the next stage continues. The event store is the source of truth within your application. Unlike a typical data structure of tables and relations ina database, an event has a much simpler model.
At a minimum, it contains an event id, aggregate root id and the payload of the event. Although typically you would store other information such as the version number relating to the state of the aggregate when the event was applied. I would suggest depending on the type of application it is also wise to include the id of the user who initiated the operation. There are trade-offs related to how much data to include in a single event. But I tend to err on the side of adding more data.
The event sourcing pattern lends it’s self to highly performant and simple database operations.
Side note:
There are only very limited queries that are likely to be performed on an event store. Typically you will find a get by aggregate id and you may need to be able to stream the entire event store for very specific purposes. As such the databases do not need to be expensive relational systems. This can have major cost-saving implications which could be a major business factor.
Temporal Queries
There is one type of query to which event sourcing lends its self. This is referred to as temporal queries. Event sourcing makes it possible to see how things have changed over time. It is possible because of the strict order of event storage necessarily in an event sourcing system. This is certainly an advantage event-sourced applications have over state-based systems and should be considered as one of the key trade-offs of these types of software systems.
7. The events are published onto the Bus or Message Router
Unlike commands which only trigger 1 command handler, events can be routed to multiple projectors which de-normalise the data to the read model. This enables you to build up very flexible optimised read models which support simple and performant queries.
It’s important to note that events represent something that HAS happened. They should be named accordingly. Using CQRS gives the developer the opportunity to name things like commands and events in such a way as to be understandable to a domain expert. If you want to know more about how to name events well then check out this post: 6 Code Smells with your CQRS Events – and How to Avoid Them
8. De-normalisers build up the Read Model or Read Store
The concept of a de-normaliser can at first be a little tricky. The problem is that we are all trained to think in ‘entities’, ‘models’ or ‘tables’. Generally, these are derived from normalised data and glued together into the form required for the front end. This process often involves complex joins views and other database query techniques. A de-normaliser on the hand translates certain events into the perfect form required for the various screens in your system. No joins required at all, ever! This makes reads, very fast and is the basis behind the claim that this style of architecture is, almost, linearly scalable.
This data is stored in the read database which is sometimes referred to as the reporting database. The read database can be a standard relational database but can equally be built up with a document database or depending on the requirements a graph database. There may even be requirements that lend themselves to multiple types of database.
Most people begin to get twitchy at this point when they realise that duplicate data may exist in the read model. The important thing to remember is that the ‘event stream’ is the only source of truth and there is no (or should be no) accidental duplication within it. This architecture allows you to re-create the entire read model or just parts of it, at will.
9. Data Transfer Objects are persisted to the Read Model
The final phase of the de-normaliser is to persist the simple DTO’s (data transfer objects) to the database. These objects and essentially property buckets and usually contain the ID of the aggregate they are associated with and a version number to aid in concurrency checking. These DTO’s provide the information the user requires, in order to form new commands and start the cycle over again.
All this results in a Highly Optimised Read Side Model
The read/query side is entirely independent of the commands and events, hence CQRS (Command Query Responsibility Segregation). The query side of the application is designed to issue queries against the read model for DTO’s. This process is made entirely trivial due to the de-normalisation of the read data. The models serve different clearly defined purposes. This clear command query responsibility segregation creates compartments within your code. Each compartment is easier and simpler to work with for having been separated out. You just need to think in terms of the command query loop rather than DTO’s and object-relational mapping. This greatly simplifies the architecture and practical code at the source level.
A. User requests data
All the data is optimised for reading. This makes querying very simple. If you require values for a ‘type-ahead drop-down list’, just get the data from an optimised list designed especially for the task. No extra data needs to be supplied apart from that required to drive the dropdown. The helps keep the weight of the data payload light which in turn helps the application remain responsive to the user.
B. Simple Data Transfer Objects
The read model just returns simple and slim DTO’s that is, as I said before easy to work with on the front end. There is however a question over whether there should be a one to one read model for every screen. In my experience, this isn’t necessary and can create a lot of duplicate code. I found it easier to create some related models which contain the data commonly needed. I found a great deal of reuse which saved time. Unfortunately, there isn’t a clear rule of thumb. This is something you will get better at with experience.
Incidentally, this also makes the implementation of a microservices architecture significantly simpler.
In Conclusion
CQRS’s biggest hurdle is it’s perceived complexity. Don’t be fooled by all the steps above. Unlike a ‘simple CRUD’ approach which starts off simple but quickly gains in complexity over time. This approach remains relatively resistant to increased complexity in the scope of the application.
Great read in combination with the previous post on concurrency issue handling in CQRS.
Thanks – glad it was usefull
Great article !!!
I am working on CQRS+ES based project based on Microservices Architecture. This post helped a lot understanding CQRS. Would have been great with a coding example.
Thank you very much for those articles. They really help to understand how things work. Lacking some code samples sometimes. For basic example of transformation to DTO. I couldn’t understand the idea behind persistence part. You persist only the diff of previous and new state of AR into events store? Or you save the actions which should be applied to previous state of AR and the actual received payload from the UI?
Another question is about domain logic. It should be implemented in command handlers or in AR?
Last question is about read model regeneration. If read database is pretty big and downtime is not a solution, how would you regenerate read model in this case and avoid out-of-sync issue?
By the way, would be nice to see explanation on failed situations, how to behave if such situations take place at any point of this process.
How to detect that read models are out of sync?
As I understand this is not the issue of the pattern, but infrastructure problem instead. Fault tolerance is very important in this pattern as I can see.
Thank you.
In some picture explaining eventstorming, beside the events which are trigger in the AR, because an user trigger a command for the UI, there’s also events that appears because time policies or external system. My question is where should those events be trigged? Still AR or something else?
Events triggered by time policies are an interesting use case. If they are from within your application, could or should they be commands and therefore handled as such? Or are they triggered from within an AR, in which case they would be handled as usual.
External events are a different matter. I would be tempted to borrow from the idea of an anti-corruption layer. Usually used to translate from one bounded context into another but in this case to translate the external event into something which makes sense for your system. This would give you a degree of protection if the signature of the event changed at some point in the future.
Hello. Nice explanation, the bonus should be a sample project.
Very bad explained. I have very good knowledge of both, but when I’ve when through as reference, I don’t understand nothing.
Hey Igor, I’m sorry to hear that. What specifically don’t you understand. Maybe I can help clarify it for you.
Hi, I’m interested on getting your thoughts on the number of read models per screen. I often hear “one model / view per screen”, and in simple cases (and most examples) that is the case.
But there can be more complicated screens. Say a screen that displays an order, and also displays a list of delivery companies that can service the order. Would you:
– Create two read models, say OrderDetailsView and DeliveryCompaniesView and call two queries when populating the UI: GetOrderDetailsQuery and GetAllDeliveryCompaniesQuery.
– Or, create a single query and read model based on the screens purpose ie. GetAssignDeliveryCompanyToOrderQuery and AssignDeliveryToOrderView, that contains both the order details and delivery companies. I lean towards the first but would be interested in you thoughts.
Hey Danial,
Great post BTW.
I just wanted to ask do you have any repo of demonstrating this in a more practical way? Because at last we need to write code, so I just wanted to know that is there any repo that I can refer to while reading the blog post and then I think it will be more understandable.
That’s a good idea. Take a look at https://github.com/gregoryyoung/m-r
How do you handle the effect of replay of events on the Read Model in case of rebuilding of Aggregate Root?
Good question. Only new events are published. So when rebuilding an aggregate these are loading from history. When a command is then issued, new events are created as a reaction to that command. Only those events are then published.
Thanks for the great post 🙂
How do you keep encapsulation of aggregate state (no getters) if you sometimes you need to enrich your domain events with some state to create for example integration events with more data?
That may suggest the boundaries of your aggregate are a little off. Each aggregate should have all it needs internally.
This is tremendous. I signed up for your web site. Thanks for all of the fantastic materials. if not an imposition, just curious, what tool did you use to make the flowchart in this post? Thanks in advance. Hunter
I made it in canva. Glad you liked it.