If you’ve been developing for any length of time you’ve probably had to create an audit log. Here’s the question though, are any of these logs, a 100% provable audit of all changes in the system? I’m guessing not. With event sourcing, a 100% provable event log just happens to be a handy by product. So how does it work and how can you implement it?
In this post I’m going to assume a web based line of business application. Event sourcing and CQRS commonly go together but today I’m going to use CRUD (create, read, update and delete). Yes thats event sourcing with CRUD! You can grab a visual studio sln with working code with download button at the end of this article.
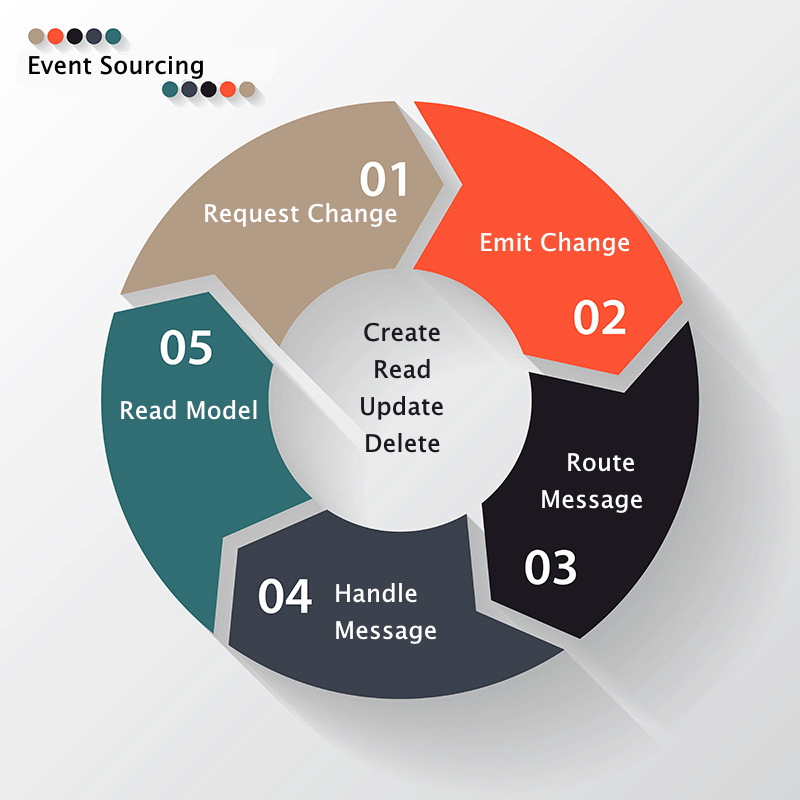
1. Request To Change
In a typical MVC architecture, a controller receives a request in the form of a model. This model represents the change (often some form of viewmodel). Assuming it passes basic validation, it is then handled in the controller. In my opinion this violates the ‘Single Responsibility’ principle found in the SOLID guidelines. This extra responsibility is better delegated to another class. If you are learning CQRS, you would create a command. The command would then be sent via a bus or message router and handled elsewhere. For simplicity I’m going to handle the business logic within the controller.
2. Apply the Business Logic and Publish the Event
This is a 3 step process. The first is to ensure the action can happen. In other words, there is no reason within the application that the action should fail. This is also when any processing, lookups or calculation takes place. Assuming the action can happen, the second step occurs. You then create the event message, and save it to disk. Only if the save is successful, the final step takes place. This is to publish the event to the message router or bus. At this point, rather than creating a new class you could just use the original model. This differs from what we usually see in a controller. The update request would flow down to a business logic layer. This in turn would pass it down to a data access layer to update the underlying data source via a repository.
3. The Message Router
The role of the router is to inspect the message and deliver it to the appropriate handlers. Because all messages go through this ‘gateway’ it offers an opportunity to add extra steps rather like a pipeline. If you are familiar with ActionFilters in ASP.Net MVC then this should sound familiure. You can inspect incoming events and apply pre-processing to them. For example, using the specification pattern, you can apply security rules before forwarding the message. I have also used this approach in other projects to carry out system logging and performance monitoring. It is also a useful place to handle exceptions. If the flexibility of creating a message router are not required then you do not strictly need to use one. In this case you could just call all the appropriate message handlers directly. For a simple system this may in fact be a more pragmatic approach.
4. Message Handlers
Message handlers are the only part of the system that changes the read model. In a CQRS architecture they are refered to as de-normalisers.They receive an event messages and then update the read models based on the data in the message. The flow would be:
a) Receive an update Person request
b) Load Person by id from the data store
c) Change the appropriate fields
d) Save the the Person object to disk
5. The Read Model
The read model is the basis of any view models. An advantage of CQRS would be that you could do away with view models and ensure that there would always be a read model, of the required shape. In the absence of CQRS, many MVC applications end up converting between, viewmodels, models and finally to tables in an RDMS. This is often done via services like AutoMapper and various ORM’s such as Entity Framework or NHibernate. This sneaking complexity overtime has the bad habit of turning what was once a simple architecture into a complex beast.
Conclusion
I made the claim that this approach is 100% provable, so how would you prove it? Answer – re-run all the events and write out the changes to a new database. Then compare the new database with the original. If there are no sneaky updates happening outside of the event messages, then both databases will be identical.There are all sorts of other interesting benefits to this approach beyond the 100% audit log, such as:
- Event playback – This allows you to create new read models from existing data. You can even project into new types of data store like a graph, document or even object database.
- Debugging – Roll back to just before the error occurred and then step through the action that failed.
- Scaling – You can send event messages over the wire to read models stored on other load balanced machines. This makes sense when you consider the number of reads in a line of business application compared to the writes. These other machines can also located close to the source of the traffic. This helps improve response times. This does impact the UI and you should ensure you have a good strategy in place to handle **eventual consistency**.
- Security – All events go through the 1 gateway and can be security filtered. I suggest using the specification pattern here to make readable and composable security rules.
- Performance monitoring – Again it’s trivial to attach timers to messages. Monitoring this timing data can provide early warnings of performance issues. This can trigger alerts if outside stated bounds.
- No data loss – Traditional systems store the current state. Event sourcing in contrast stores the state change. The state change can hold valuable data which is otherwise hard to capture.
It is also interesting to note that event sourcing can be used without CQRS.
Have you ever tried to build an audit log? Would event sourcing have solved the issues you faced? What other approaches are there to solve this problem?
cqrs, CRUD, event-sourcing, eventual-consistency